Github Link:
Task 2 and Evaluation Policy
Task 2 includes two subcompetitions: CIFAR-10N and CIFAR-100N. Each team can choose to participate in any subcompetitions.
Task 2: Label Noise Detections
1. Background
Label noise in real-world datasets encodes wrong correlation patterns and impairs the generalization of deep neural networks (DNNs). Employing human workers to clean annotations is one reliable way to improve the label quality, but it is too expensive and time-consuming for a large-scale dataset. One promising way to automatically clean up label errors is to first algorithmically detect possible label errors from a large-scale dataset, and then correct them using either algorithm or crowdsourcing.
2. Goal
The goal is to encourage the design of an algorithmic detection approach to improving the corrupted label detection (a.k.a, finding label errors) on CIFAR-N.
This task does not have specific requirements on the experiment settings, i.e., the model architecture, data augmentation strategies, etc. However, the use of clean labels or pre-trained models on CIFAR datasets, or any other datasets, is not allowed.
3. Evaluation Metric
The performance is measured by the F1
-score of the detected corrupted instances, which is the harmonic mean of the precision and recall, i.e.,
Let vn
=1 indicate that the n-th label is detected as a corrupted label, and vn=0 otherwise. Then the precision and recall of finding corrupted labels can be calculated as:
Note
The hyperparameter settings should be consistent for different noise regimes in the same dataset, i.e., there will be at most two sets of hyperparameters, one for CIFAR-10N (aggre, rand1, worst), one for CIFAR-100N.
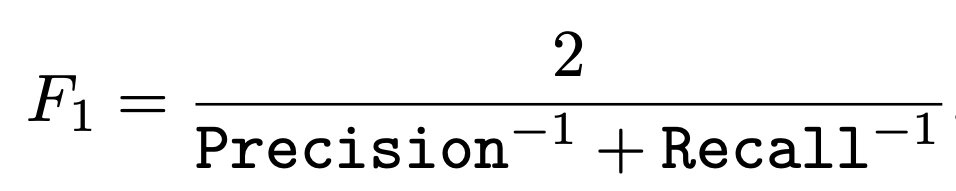
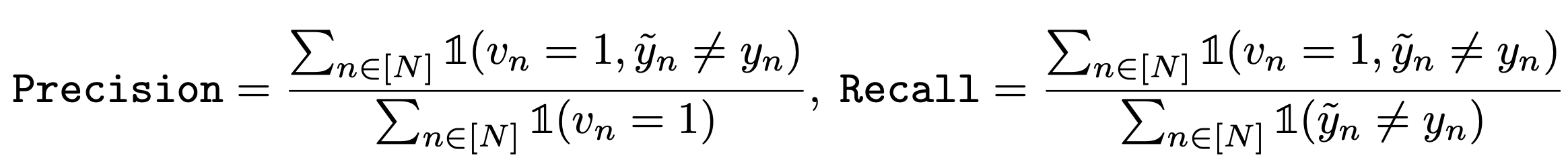
4. Requirements
- Participants can only use standard training images for CIFAR and the CIFAR-N noisy training labels;
-
Can not use CIFAR-published training labels, test images, and test labels, to perform training and model selection;
- Participants can use our provided additional information (i.e., worker-id, work-time available at this Github).
- Learn from scratch. Any pre-trained model can not be used.
5. Submission Policy
Code Submission and Evaluation
- Participants must submit reproducible code with a downloadable link, e.g., GitHub;
-
The script run.sh for running the code must be provided.
- Environments must be specified in requirements.txt.
- We will run run.sh with 5 pre-fixed seeds. Each run will be evaluated w.r.t. a random selected subset of CIFAR-10/CIFAR-100 test data with replacement, and take the average performance of 5 runs. Each run should output a file named detection.npy, the example formt is included in Line 52-59 in the file detection.py.
- For CIFAR-10, there are three noise types: rand1, worst, aggre. Each participant will receive three ranks. No submission equals the last rank. Our evaluation metric is similar to Borda Count, and the score of the i-th rank is given by max(11-i, 0). The accumulated scores over three noise regimes determine the final score.
- For CIFAR-100, there is only one dataset. The average performance over 5 seeds determines the winner.
- We will test the performance by detection.py for the learning task.
IMPORTANT:
This competition is time-constrained. We do not recommend spending too much time on CIFAR. Thus the training will be stopped at 10xBaselineTime. The baseline code (train with cross-entropy and ResNet34) is available at ce_baseline.py. For example, if you take 1 hour to run ce_baseline.py in your device, your method should not be longer than 10 hours. We will use the best model selected by noisy validation data within 10xBaselineTime.